Automatic Speech Recognition Explained: Everything You Need to Know About ASR

Ever wonder how your phone knows what song to play when you say “Hey Siri”? Or how your car can dial your mom without you touching the screen? That’s not magic – it’s Automatic Speech Recognition (ASR), also known as speech-to-text technology.
ASR acts as the invisible bridge that transforms human speech into text that machines can understand. It’s one of the most important breakthroughs in human-computer interaction, making technology more natural, accessible, and intuitive. From virtual assistants to real-time transcription services, ASR has become a core part of our digital lives—and its future is even more exciting.
What is Automatic Speech Recognition (ASR)?
At its core, Automatic Speech Recognition is the process of converting spoken language into written text using machine learning and computational linguistics.
You may also hear it called speech-to-text or voice recognition. While the terms are often used interchangeably, ASR specifically focuses on understanding natural human speech and rendering it accurately into text.
Unlike humans who effortlessly interpret words, tone, and context, machines need algorithms to:
- Detecting sound patterns.
- Convert sound waves into digital signals.
- Map those signals to linguistic units (like phonemes and words).
- Interpret them into coherent text.
This ability allows ASR to perform tasks like:
- Following voice commands.
- Transcribing calls, lectures, or interviews.
- Supporting real-time communication through captions.
The result? Hands-free convenience and accessibility at scale.
How Does Automatic Speech Recognition Work?
Think of ASR as a production line for speech: raw audio enters on one side, and polished, readable text comes out the other. This happens in a matter of milliseconds, thanks to powerful AI models.
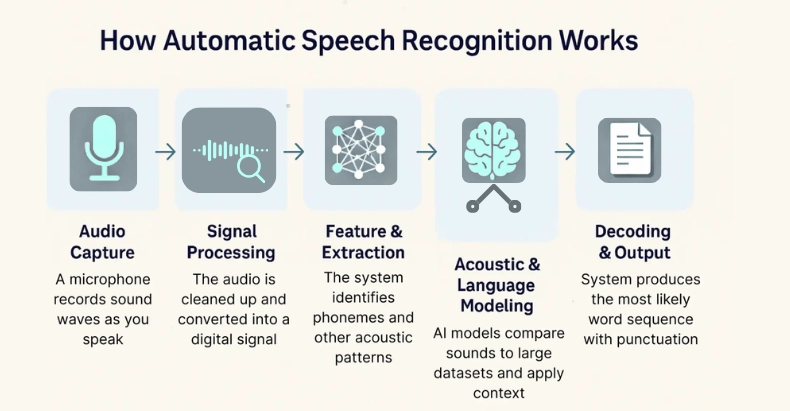
Here’s a simplified breakdown of the ASR pipeline:
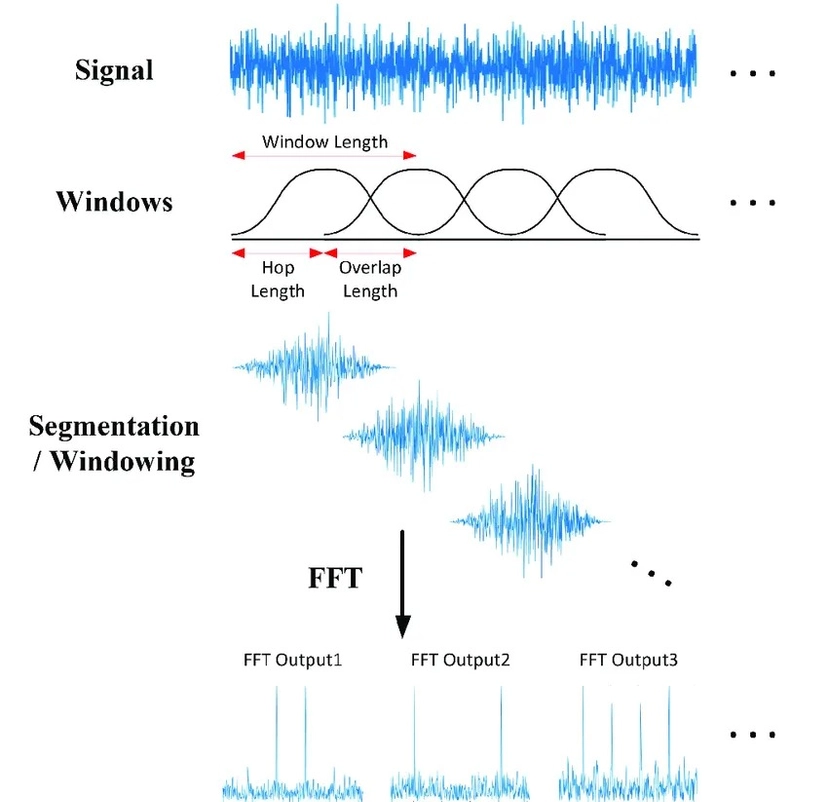
1. Feature Extraction – Preparing the Audio
The first step is acoustic preprocessing, which converts raw sound waves into a format that’s easier for models to understand.
- Modern ASR systems often use log-Mel spectrograms rather than older techniques like MFCCs.
- These representations capture both frequency and time-based information, allowing models to recognize subtle sound differences.
- Advanced models such as wav2vec 2.0 even skip traditional steps, learning features directly from the waveform.
2. Encoder – Learning Acoustic Representations
Once features are extracted, they pass through an encoder, which compresses them into high-level patterns.
- Early ASR relied on RNNs and LSTMs, while modern systems prefer Transformers and Conformers.
- The encoder learns both short-term sounds (like syllables) and long-term dependencies (like sentences).
3. Decoder – Turning Features into Text
The decoder generates the final transcription by predicting characters, words, or subwords.
- It works step by step, often using attention mechanisms to focus on the most relevant part of the audio.
- Models trained with CTC (Connectionist Temporal Classification) or RNN-T handle timing alignment between speech and text effectively.
4. Language Model Integration – Adding Context
Even the best acoustic models can misinterpret similar-sounding words. That’s where a language model (LM) comes in.
- For example, “I scream” vs. “ice cream.”
- By incorporating context, external LMs help disambiguate confusing phrases and ensure domain-specific accuracy.
Together, these steps enable real-time, highly accurate speech-to-text performance.
Approaches to ASR Technology
1. Traditional Hybrid Models
- Combine acoustic, lexicon, and language models.
- Reliable but less adaptive to new domains or languages.
2. End-to-End Deep Learning Models
- Directly map speech to text using neural networks.
- Faster, require less manual tuning, and deliver superior accuracy.
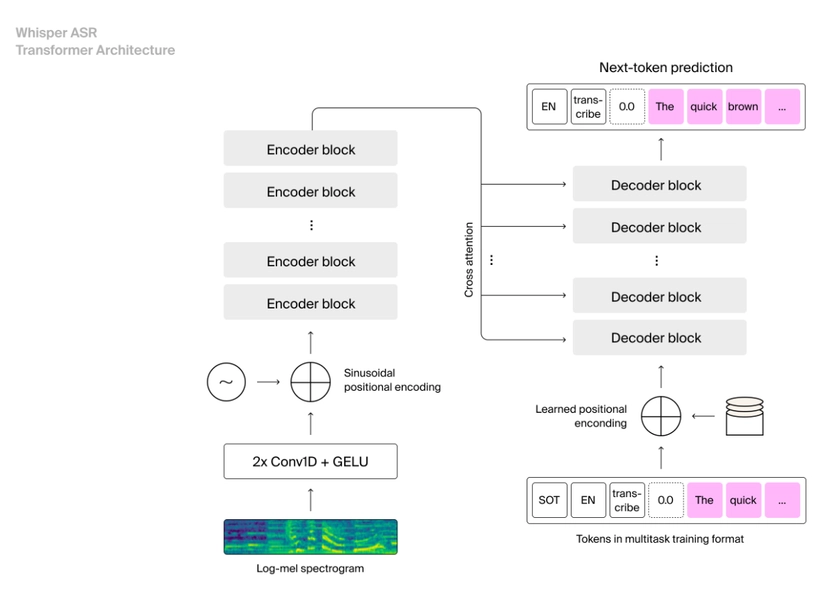
- Examples: Whisper by OpenAI, RNN-T, and Conformer-based systems.
The shift toward end-to-end models has revolutionized ASR by cutting down complexity while improving scalability across industries.
Benefits of Automatic Speech Recognition (ASR)
The power of ASR extends far beyond convenience. Here are some of its most impactful benefits:
- Accessibility: ASR opens up the digital world to people with hearing or mobility impairments. Automatic captions on videos, voice navigation, and real-time transcription empower inclusivity.
- Productivity: Businesses save hours with instant transcriptions of meetings, customer calls, and lectures. Instead of typing notes, professionals can focus on conversations.
- Efficiency: Industries like healthcare, finance, and customer service use ASR to digitize spoken data, speeding up workflows and reducing human error.
- Enhanced User Experience: Virtual assistants like Alexa, Google Assistant, and Siri thrive because of ASR, making everyday tasks—like setting reminders or controlling smart homes—effortless.
- Data-Driven Insights: Speech-to-text technology transforms conversations into analyzable datasets, unlocking opportunities in sentiment analysis, compliance, and performance tracking.
Applications of Speech-to-Text and ASR
Automatic Speech Recognition has countless real-world applications. Some key examples include:
- Customer Service: Call centers use ASR to automatically transcribe customer interactions, enabling agents to focus on problem-solving instead of note-taking.
- Healthcare: Doctors can dictate patient notes hands-free, reducing burnout and improving documentation accuracy.
- Education: Real-time closed captioning makes learning accessible for students with disabilities and helps all students retain lecture material.
- Legal & Media: ASR simplifies archiving, searching, and analyzing large volumes of spoken data, from courtroom recordings to podcasts.
- Smart Devices & IoT: From voice-activated appliances to cars with built-in assistants, ASR enables intuitive, hands-free interaction.
- Finance: Speech-to-text assists in fraud detection, voice authentication, and secure transactions, making banking more secure.
Challenges in Automatic Speech Recognition
While ASR has advanced significantly, it isn’t perfect. Common challenges include:
- Accents & Dialects: Models often perform best on standardized accents, struggling with regional variations.
- Background Noise: Environments like busy cafés or call centers reduce accuracy. Noise cancellation helps, but not always perfectly.
- Code-Switching: Many users mix languages in a single sentence. Most ASR systems still struggle with this.
- Domain Vocabulary: Specialized jargon (like medical or legal terms) is hard to capture without customized training.
- Privacy Concerns: Always-on devices raise questions about data storage, consent, and compliance with privacy laws. This has fueled demand for on-device ASR that keeps data local.
The Future of Automatic Speech Recognition
The future of ASR is set to be smarter, faster, and more context-aware. Key trends include:
- End-to-End Neural Models: Architectures like Whisper and RNN-T simplify training and improve both speed and accuracy.
- Multilingual and Code-Switching Support: ASR systems are being trained on diverse datasets to handle multiple languages seamlessly in one conversation.
- On-Device Processing: Running ASR locally enhances privacy, reduces latency, and ensures functionality even offline.
- Multimodal Integration: Future systems will combine speech with other cues (like gestures or visuals) for immersive AR/VR experiences. Imagine giving voice commands in a virtual classroom or operating room.
In essence, ASR is moving beyond transcription into true conversational AI, where systems don’t just recognize words but also intent and emotion.
Conclusion
Automatic Speech Recognition and speech-to-text technology are no longer futuristic—they’re part of our daily lives. From accessibility tools to smart devices, ASR is transforming the way humans interact with technology.
For businesses, the opportunity is enormous:
- Define your use case clearly.
- Evaluate providers for accuracy, adaptability, and privacy.
- Plan for integration into long-term digital strategies.
As models become more sophisticated, expect ASR to blend seamlessly into every industry, making our digital world not only more efficient but also more human-centered. The future of ASR isn’t just about machines understanding our words – it’s about them understanding our intent, context, and needs.

Bio: Harish Kumar is a data-driven professional with 3.7+ years of experience in analytics and product management, having worked across startups like Noon, Zomato, and Junglee Games. He specialises in turning data into actionable insights, driving growth, and building scalable systems from the ground up. Passionate about solving complex business problems and creating measurable impact, he currently explores opportunities in analytics, product strategy, and business growth.