Voice AI, TTS & Type-to-Speech: Quietly Reshaping How We Communicate
Most people first encounter Voice AI through a voice assistant. You say something. It responds. Simple enough. But what happens in the middle is a lot more sophisticated than it looks.
Voice AI refers to any AI system that can process, interpret, or generate human speech. That includes systems that listen and understand spoken input (speech to text), systems that speak back from written content (text to speech), and systems that manage the full conversation loop from input to response to output.
The reason Voice AI feels so different today compared to three or four years ago comes down to one thing: neural models. Older voice systems were rule-based. They matched patterns. Modern systems have learned from millions of hours of real human speech and understand things like context, tone, rhythm and intent.
The best Voice AI does not just process language. It understands the weight behind it. When someone says "I need help," it knows that is not the same as "I have a question."
These numbers point to something real. Voice is becoming the default interface for a growing number of digital interactions. The products that get this right will feel native to how people actually communicate. The ones that get it wrong will feel like a chore.
What Text to Speech/ Type to Speech really means in 2026
Text to Speech has been around for decades. But the version that existed even five years ago is barely recognisable compared to what is possible today.
At its core, Text to Speech (TTS) is the process of converting written text into spoken audio. Feed in a sentence. Get back a voice. That part has not changed. What has changed is everything about the quality, expressiveness, and speed of that conversion.
Modern TTS systems do not just read. They perform. They know that a question ends differently from a statement. They can adjust pacing, warmth, and weight based on what the content actually needs.
The practical value is bigger than most people realise
Content teams are using TTS to produce audio versions of every article they publish, without booking a studio. E-learning platforms are building full courses in 30 languages without a voiceover artist. Healthcare providers are delivering post-appointment instructions in a patient's own language at the click of a button.
These are not edge cases. They are the normal applications of a technology that has matured to the point where quality is no longer a barrier.
At Shunya Labs, the focus has been on naturalness at scale. Not just one good voice, but a system that sounds right across accents, languages and content types. When you read a sentence back to yourself and it sounds like someone said it rather than something read it, that is the bar we are holding ourselves to.
These technologies are strongest when they work together
Voice AI, Text to Speech or Type to Speech are not competing. They are complementary. Each addresses a different point in the communication chain.
Voice AI handles understanding and generating language. Text to Speech handles the conversion of that language into natural audio and handles the real-time delivery of that audio during live interactions.
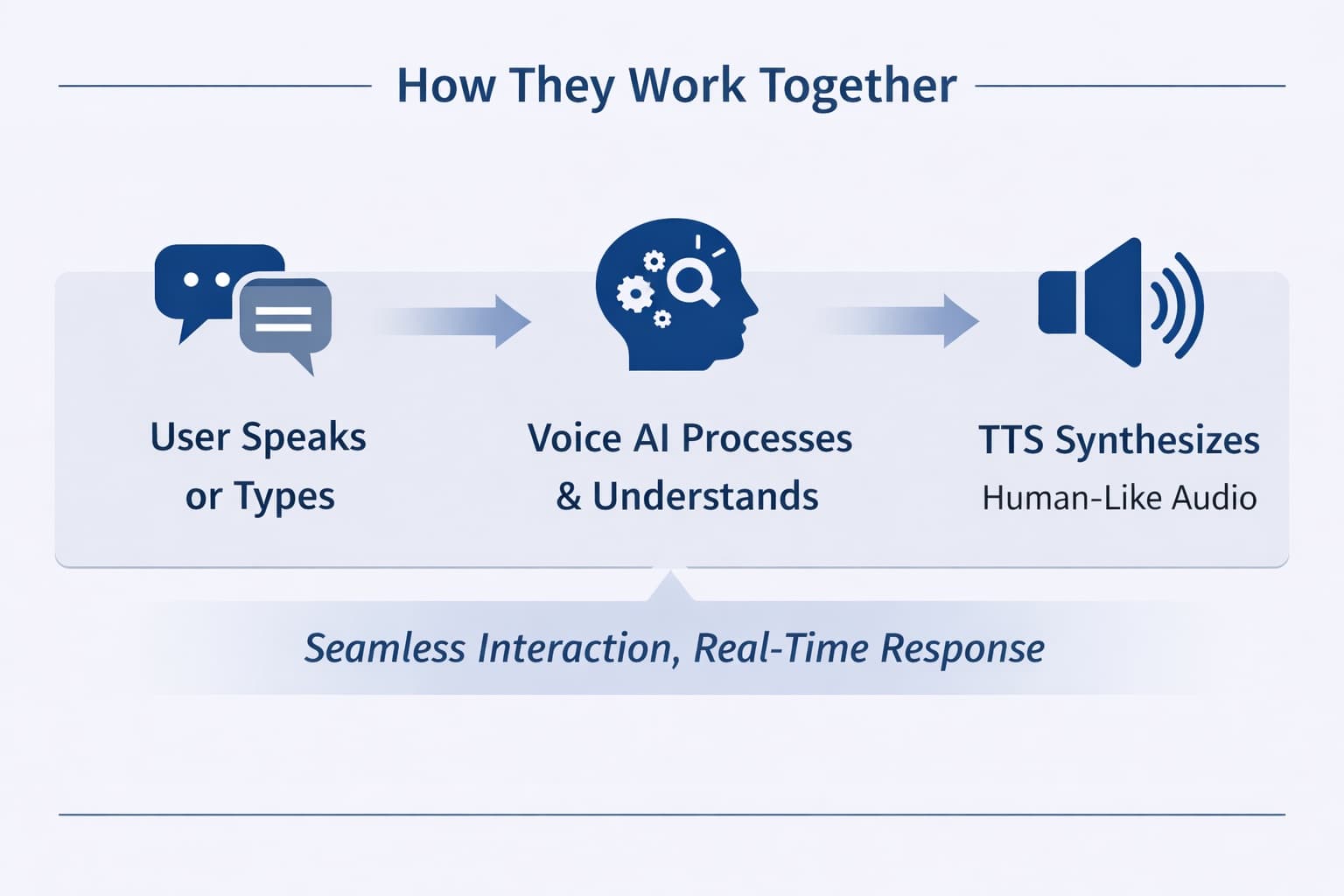
A well-built voice application uses all. A user speaks or types a question. The Voice AI interprets it and generates a response. The TTS engine renders that response in a voice that sounds human. If the interaction is live, the Type to Speech layer ensures there is no uncomfortable gap between response and delivery.
Getting this stack right is harder than it looks. Each layer needs to perform well independently and hand off cleanly to the next. A great TTS model plugged into a slow Voice AI pipeline can still produce a bad experience. The quality of the whole system depends on the quality of every part.
This is where Shunya Labs puts its energy. We are not building one piece and calling it done. We are building the full stack with the same level of care at every layer. Our speech to text model handles accurate transcription across accents and noise conditions. Our TTS model is designed to match that same standard for naturalness and reliability. And the architecture underneath both is built for real-time performance.
What strong voice AI looks like in practice
It is easy to talk about voice quality in abstract terms. Here is what it actually looks like when a voice AI platform is doing its job properly.
A call centre agent powered by voice AI picks up on the frustration in a customer's voice and routes them to a human before they have to ask. A language learning app speaks back a student's sentence with natural rhythm, not just correct phonemes. A content platform reads an article in a voice that matches the publication's tone, not a generic neutral default.
These outcomes require more than a decent model. They require latency that does not make interactions feel laggy. They require multilingual support that actually works across dialects, not just primary languages. They require the ability to fine-tune or customise voice output to fit a brand or context.
Shunya Labs is built with these outcomes in mind. Not as feature checkboxes but as the standard we design around.
Where voice technology is heading and what it means for you
The near-term direction is clear. Models are getting faster. Personalisation is getting deeper.
A few things worth watching over the next 12 to 18 months:
- •Emotion-aware synthesis. TTS systems that adjust tone and pacing based on the emotional weight of the content, not just the words.
- •Multilingual voice at production quality. Not translation-quality audio but broadcast-quality output across 50 or more languages from a single input.
- •Custom brand voices. Businesses create unique AI voices that are consistent across every customer touchpoint, from support calls to product narration.
- •Ambient voice interfaces. As more devices become voice-first, the interaction layer shifts from screen to speech for a growing share of daily tasks.
- •Fully integrated voice agents. AI systems that listen, reason, and respond in speech in real time, with the full context of a conversation maintained throughout.
Each of these directions places more weight on the quality of the underlying voice models. The teams and platforms investing in that quality now will be the ones positioned to build on it when these use cases become standard.
At Shunya Labs, that investment is already underway. With our capabilities of building custom full stack models, we are building toward a platform that handles the full voice layer for the products and teams that need it.
Final thought
Voice AI, Text to Speech and Type to Speech are names for specific tools. But they are all working toward the same thing. Communication that does not feel like a workaround.
The gap between how humans talk to each other and how they talk to technology has been closing for years. In 2026, that gap is smaller than it has ever been. The tools are good enough now that the focus can shift from "does this work" to "does this feel right."
That is the question driving the work at Shunya Labs. And it is a question we think the industry is finally ready to answer well.
- Dutoit, T. (2011). High-Quality Text-to-Speech Synthesis: An Overview.[online] Journal of Electrical and Electronics. Available at:https://scholar.google.com/citations?view_op=view_citation&hl=en&user=xxpvjOUAAAAJ&citation_for_view=xxpvjOUAAAAJ:qjMakFHDy7sC
- Ruby, D. (2023). 65 Voice Search Statistics For 2023 (Updated Data).[online] Demand Sage. Available at:https://www.demandsage.com/voice-search-statistics/
- Trivedi, A., Pant, N., Shah, P., Sonik, S. and Agrawal, S. (2018). Speech to text and text to speech recognition systems-A review.
- Webuters.com (2025). AI Statistics 2025: 100+ Stats That Show Where AI Is Headed.Available at:https://www.webuters.com/ai-statistics
References

Navvya Jain
Research & Product Analyst, Shunya Labs
Bio: Navvya works at the intersection of product strategy and applied AI research at Shunya Labs. With a background in human behaviour and communication, she writes about the people, markets, and technology behind voice AI, with a particular focus on how speech interfaces are reshaping access across emerging markets.