What Is ASR? The Technology Behind Every Voice AI Product


TL;DR , Key Takeaways:
- ASR stands for Automatic Speech Recognition. It is the technology that converts spoken audio into text. Every voice AI product, from phone bots to meeting transcription tools, depends on it.
- Modern ASR or STT (Speech to Text) uses deep learning, specifically Conformer and Transformer architectures, to turn audio waveforms into accurate text in milliseconds. The old rule-based systems of the 1990s are gone.
- Accuracy varies enormously by language, audio quality, and what the model was trained on. A model scoring 5% WER on US English can exceed 25% WER on Indian regional languages over phone audio.
- For India, the speech AI market is growing at 23.7% CAGR. But most global ASR platforms were not built for Indian languages, dialects, or the audio conditions of Indian deployments.
- Shunya Labs covers 200 languages including 55 Indic languages, trained on real audio.
When you speak to a bank’s customer care bot in Hindi and it understands you, something specific is happening before any AI logic kicks in. Your voice is being converted to text. That conversion, fast and accurate enough to feel seamless, is ASR.
ASR stands for Automatic Speech Recognition. It is also called speech to text, or STT. It is the foundational layer inside every voice AI product: voice agents, meeting transcription tools, call analytics platforms, speech-enabled mobile apps, and IVR systems. Without it, voice AI does not exist.
Despite being everywhere, ASR is poorly understood outside the people who build voice systems. This post explains what it is, how it works, and what determines whether it is good or bad. It also covers what the speech AI landscape in India looks like in 2026.
$9.66B
Global speech AI market, 2025
Projected $23.11B by 2030 at 19.1% CAGR
$1.13B
India ASR market, 2024
Projected $8.19B by 2033 at 23.7% CAGR
900M
India internet users, 2025
98% access content in Indic languages
What ASR Actually Does
At its core, ASR takes audio as input and produces text as output. That sentence sounds simple. The engineering behind it is not.
When you speak, you produce sound waves. Those waves travel through air and hit a microphone, which converts them into a digital signal. The digital signal is a sequence of numbers representing sound pressure over time. ASR takes that sequence of numbers and figures out which words you said.
The reason this is hard: spoken language is continuous. There are no clean gaps between words, the way spaces appear between words in text. Speakers vary in accent, speed, and pronunciation. Background noise blends with the speech signal. Two people saying the same word in different accents produce very different waveforms. And the same waveform can map to different words depending on context. The word ‘bat’ and the word ‘bad’ sound nearly identical in certain accents.
ASR solves all of these problems simultaneously, in real time, on audio that nobody cleaned up for it. That is the engineering challenge that took decades to make usable.
A Brief History: From Rules to Neural Networks
The first ASR systems appeared in the 1950s. Bell Labs built a system called Audrey in 1952 that could recognise spoken digits from a single speaker. It worked by matching incoming audio against pre-recorded templates. Slow, rigid, and useless for anything except that one speaker’s digits.
For the next four decades, ASR ran on a framework called Hidden Markov Models, or HMMs. These were statistical models that learned which sequences of acoustic units, called phonemes, corresponded to which words. HMMs got good enough to power phone-based IVR systems in the 1990s and early 2000s. Press 1 for billing. Press 2 for support. Say your account number now. You know the experience. It worked, barely, for constrained vocabularies in quiet conditions.
The shift happened between 2012 and 2016. Deep learning arrived in ASR. Researchers showed that neural networks could learn directly from audio-text pairs without needing hand-crafted phoneme definitions. In 2015, Baidu’s Deep Speech achieved error rates that rivalled humans on clean audio benchmarks. The old architecture was replaced almost overnight.
Today’s ASR systems use architectures called Conformers and Transformers. Conformers combine convolutional neural networks for local acoustic pattern detection with Transformer attention for long-range context. They power the most accurate production ASR systems available.
Mobile typing speed in Indian languages is 18 to 23 words per minute. Natural speech is 130 to 150 words per minute. Writing is a trained skill. What people can say clearly becomes harder to type. Voice removes this friction. (CXO Today, December 2025)
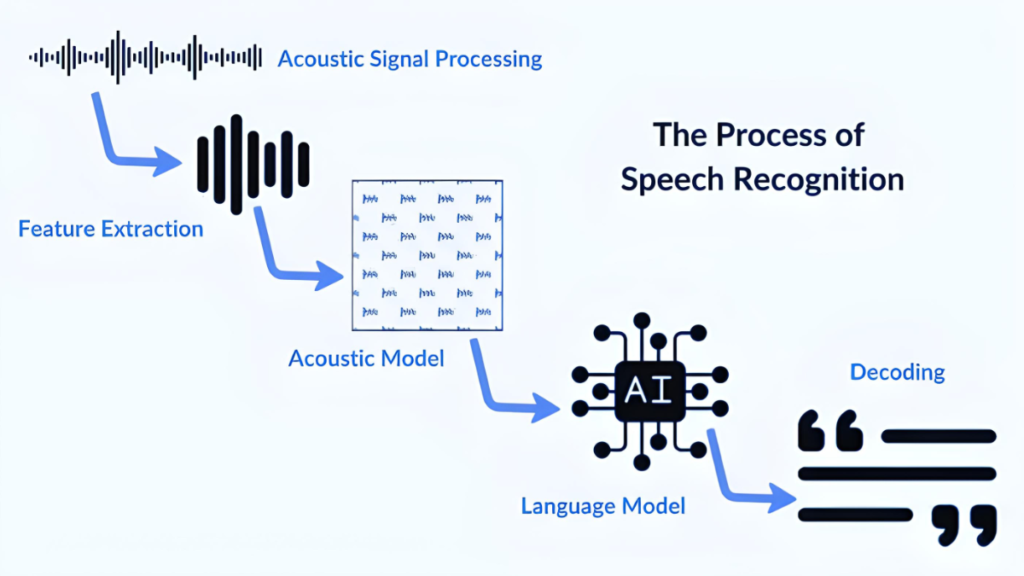
How Modern ASR Works: The Three Stages
Every modern ASR system processes audio in three conceptual stages, even if the boundaries between them are blurry in end-to-end neural systems.
Stage 1: Acoustic processing
Raw audio is converted into a compact representation that captures the information relevant to speech. The most common representation is a log-Mel spectrogram. It is a matrix showing how much energy exists at each frequency band over short time windows. A 1-second clip of audio becomes a 2D matrix of roughly 100 time frames by 80 frequency bins.
This representation strips out information irrelevant to speech, like absolute recording volume. It preserves the patterns that distinguish phonemes from each other. It is the input to the neural network.
Stage 2: The neural model
The acoustic representation passes through a neural network that produces a probability distribution over possible text outputs. In Conformer-CTC models, the network outputs a probability for each character or subword unit at each time step. The CTC, Connectionist Temporal Classification, algorithm then finds the most probable sequence of text across all time steps.
This stage is where most of the intelligence lives. The network learns, from millions of audio-text pairs, which acoustic patterns correspond to which linguistic units. It learns this separately for each language. That is why the training data language and the deployment language need to match for the system to work well.
Stage 3: Language model rescoring
The raw output of the acoustic model is often imperfect. It might confuse acoustically similar words. A language model trained on text in the target language rescores candidate transcriptions. It boosts sequences of words that are plausible given the context. In a banking context, the phrase about an EMI becomes the right transcription. A phrase about an Emmy does not.
Modern end-to-end systems sometimes skip this step by baking contextual knowledge directly into a larger model. But for domain-specific deployments like BFSI or healthcare, a domain-tuned language model still adds measurable accuracy improvements.
What Makes One ASR System Better Than Another
Two ASR systems can claim to support the same language and produce completely different results on the same audio. The differences come down to four variables.
Word Error Rate on your audio, not a benchmark
WER, Word Error Rate, is the standard accuracy metric. It measures what fraction of words in a reference transcript were incorrectly transcribed. A WER of 5% means 5 words out of 100 were wrong. A WER of 25% means one word in four was wrong.
The critical word in that definition is ‘reference transcript.’ Published WER numbers are measured on specific test sets, usually clean studio audio in standard language varieties. A model achieving 5% WER on a US English benchmark can easily produce 20 to 25% WER on Indian regional language audio over a phone. The benchmark number tells you how good the model is on the benchmark. It does not tell you how good it will be on your data.
The only WER that matters for your deployment is the one you measure on your own audio. Any ASR vendor worth considering will give you a trial on your own recordings before you commit.
Streaming vs batch architecture
Batch ASR waits for a complete audio clip before processing it. Streaming ASR processes audio as it arrives and returns text in real time, often within 100 milliseconds of a word being spoken.
For analytics and transcription of recorded calls, batch works fine. For any live interaction, a voice bot, a real-time captioning system, a voice-enabled mobile app, streaming is not optional. The architecture choice determines the minimum latency your product can achieve. Shunya Labs Zero STT supports streaming from the first audio chunk, returning a final transcript quickly for most utterances.
Language depth, not language count
A platform claiming to support 100 languages does not necessarily support all 100 at the same accuracy level. Many platforms support a small number of languages well and extend nominal support to others with limited training data and no real accuracy testing.
For India, the distinction matters enormously. Standard Hindi over clean audio is supported reasonably well by most global platforms. Bhojpuri, Maithili, Chhattisgarhi, and Odia over 8kHz telephony audio can be poorly supported by any platform that did not train on those languages in those conditions. The Shunya Labs language list shows 55 Indic languages with production-grade accuracy data, not just nominal support.
On-premise vs cloud only
Most global ASR APIs are cloud-only. Audio is sent to a remote server, processed, and a transcript is returned. For consumer applications, this is usually fine. For regulated deployments in India, particularly BFSI and healthcare, sending customer audio to servers outside India may conflict with DPDPA requirements and RBI guidelines.
On-premise ASR, where the model runs on infrastructure the enterprise controls, addresses this directly. Shunya Labs on-device model runs fully on-premise on CPU hardware, no GPU required, with the same model as the cloud version. Deployment details are at shunyalabs.ai/deployment.
Where Speech AI Is Being Used in India Right Now
The India Voice AI market was valued at USD 153 million in 2024. It is projected to reach USD 957 million by 2030, a CAGR of 35.7%. That growth is spread across several sectors where voice is already being used at scale.
CONTACT CENTRES AND CUSTOMER SERVICE
For example, Airtel runs automated speech recognition on 84% of inbound calls. Meesho’s voice bot handles around 60,000 calls daily, transcribing queries in multiple Indian languages. These are not experimental deployments. They are production infrastructure running at scale. The ASR layer is what makes them work.
BFSI
Banks and NBFCs can use ASR for outbound EMI collections, inbound balance queries, fraud detection through voice biometrics, and call quality monitoring. The Indian banking system received over 10 million formal complaints in FY23-24. Voice AI with accurate ASR can be one of the primary tools for managing this volume efficiently.
HEALTHCARE
Doctors dictate clinical notes. Hospitals run multilingual patient intake over the phone. Lab results and prescription reminders go out as voice calls. Each of these can use an ASR layer to convert spoken input or to process spoken responses from patients. The growth rate for healthcare voice AI is 37.79% CAGR globally, the fastest of any sector.
FIELD OPERATIONS
Insurance agents, FMCG reps, and microfinance field workers update CRMs, log activities, and record collections by speaking rather than typing. In Indic languages, typing speed is 18 to 23 words per minute. Speech is 130 to 150 words per minute. The productivity difference is substantial. It only works if the ASR handles the regional language the field worker actually speaks.
ASR, Speech AI, and Voice AI: What the Terms Actually Mean
These three terms appear constantly in vendor materials and often get used interchangeably. They are not the same thing.
ASR is the specific technology: the model that converts audio to text. It is a component.
Speech AI is a broader category. It includes ASR, but also TTS (text to speech), speaker diarization (who said what), speech analytics, emotion detection from audio, and other audio intelligence capabilities. When someone says they are building on a speech AI platform, they usually mean access to several of these capabilities through a single API.
Voice AI describes complete voice-enabled products or agents: voice bots, voice assistants, voice-first applications. These are built on top of speech AI. A voice AI agent uses ASR to hear the user, an LLM to reason and respond, and TTS to speak the answer. The voice AI platform is the infrastructure layer underneath all of this.
Shunya Labs is a speech AI and voice AI platform. Zero STT is the ASR product. Zero TTS is the text-to-speech product. Together they form the input and output layers for any voice AI application. The full platform overview is at shunyalabs.ai/overview .
What to Look for in a Speech AI Platform for India
If you are building something with voice, here is what to check before picking an ASR or speech AI platform.
- Test on your audio. Not the demo. Your language, your recording conditions, your callers. Ask for a free trial on real data before committing.
- Check streaming support. If you are building anything interactive, batch ASR adds 400 to 800ms of latency you cannot recover from.
- Ask for WER on the specific languages you need. Hindi is not the same as Marathi. Indian English is not the same as US English. Get benchmark data for your actual use case.
- Verify deployment options. If you are in BFSI or healthcare, understand where audio is processed and whether it meets your compliance requirements.
- Check whether TTS is available from the same platform. Mixing an accurate ASR from one provider with a generic TTS from another produces voice agents that understand well but sound foreign. Native Indic TTS matters for user trust.
Shunya Labs is built for India-first deployments.
References:
- Fortune Business Insights (2022). With 23.7% CAGR, Speech and Voice Recognition Market Size to Reach USD 49.79 Billion [2022-2029]. [online] Yahoo Finance. Available at: https://finance.yahoo.com/news/23-7-cagr-speech-voice-080500463.html [Accessed 24 Mar. 2026].
- IBEF (2025). India’s internet users to exceed 900 million in 2025, driven by Indic languages. [online] India Brand Equity Foundation. Available at: https://www.ibef.org/news/india-s-internet-users-to-exceed-900-million-in-2025-driven-by-indic-languages.
- reverie (2026). Speech Recognition System: A Complete 2026 Guide – Reverie. [online] Reverie. Available at: https://reverieinc.com/blog/speech-recognition-system/ [Accessed 25 Mar. 2026].
- Tsymbal, T. (2024). State of Conversational AI: Trends and Future [2024]. [online] Master of Code Global. Available at: https://masterofcode.com/blog/conversational-ai-trends.
- www.marketsandmarkets.com. (n.d.). Speech and Voice Recognition Market Size, Share and Trends forecast to 2026 by Delivery Method, Technology Speech Recognition | COVID-19 Impact Analysis | MarketsandMarketsTM. [online] Available at: https://www.marketsandmarkets.com/Market-Reports/speech-voice-recognition-market-202401714.html.

Bio: Navvya works at the intersection of product strategy and applied AI research at Shunya Labs. With a background in human behaviour and communication, she writes about the people, markets, and technology behind voice AI, with a particular focus on how speech interfaces are reshaping access across emerging markets.